The 'wiki' section of the site is the progress of being migrated from an old site. There are some rendering issues and many of the links don't work yet.
Proto AGI v1
Can we use our best current understanding of neuroscience to inspire AI architectures that could form an artificial general intelligence (AGI)? This page attempts to do that. It uses the results of [[A Theory of Consciousness]] as the overarching guide, along with additional biological influences.
This page presents CIPAGIO, Consciousness Inspired Proto Artificial General Intelligence Operative. It is part of a collection of documents:
Background
This page makes reference to content within other pages:
- [[Biological basis for proto AGI]]
- [[General Intelligence Classifications]]
- [[Executive Control in a proto AGI]]
- [[Autonomous Monitoring and Control]]
- [[Cooperative Competitive Systems]]
Also see:
- [[Survey of Reinforcement Learning]]
- [[Anecdotes for proto AGI]]
- [[An Investigation of Active Inference]]
Principles
Centralised
It appears that the biological brain largely produces its complex behaviour through decentralised coordination of many components. That’s hard to reason about and to build for a proto AGI.
The design for this AGI assumes centralised control.
Convergence
A multi-layered system like this will be inherently chaotic. So without explicit consideration it’s chances of converging towards a stable and useful outcome are minimal.
To counteract that the architecture must build in convergent forces that apply at multiple points. These will be applied across all layers, and across multiple time scales.
Brain growth
The human baby brain starts small, with many capabilities not fully formed. Those capabilities “come online” over time as the child grows. I believe this had two benefits:
- It helps to reduce the search space for optimal network training. Effectively it trains against a simpler problem to start with, then slowly increases the brain capacity and retrains on more complex problems.
- It helps to ensure convergence in an otherwise unstable system. With full executive control, we’ve got too much control over the reinforcement learning algorithm, but when in a fresh state, the executive control will be too unstable. So better to train level 1 systems first, holding executive control in a mostly disabled state.
In contrast, a modern neural network is static in size, thus we will not be able to replicate the same efficiency of learning. However, there may be other opportunities for improving our architecture or approach. For example, we may initially attenuate-to-zero the output of particular components, and slowly ramp up their output signal strength and their accuracy improves.
Avoiding catastrophic forgetting
Modern neural networks suffer from “catastrophic forgetting”, where training on one skill causes loss of a prior learned skill. Humans don’t suffer from this problem, as the brain seems to be able to slot different skills into slightly different regions. There is work on achieving that with AI. One promising angle is Stephen Grossberg’s Adaptive Resonance Theory (ART).
To keep things simple, for now we will ignore the issue of catastrophic forgetting, and will setup a training environment where all required skills are repeatedly re-practiced.
Executive Control and Decomposed Sandwich form of Reinforcement Learning
I think executive control incorporates a “decomposed sandwich” form of reinforcement learning - where many aspects of the algorithm are under direct control. This includes:
- Internalisation of reward function.
- Exploration vs exploitation ratio
- Control over each individual attempt.
Executive control also learns to “drive” the unseen aspects of reinforcement learning by building up a model of how it works and choosing to leverage it.
- Eg: we observe what methods of learning work best for ourselves.
- Eg: we actively choose to learn a new skill.
Evolution as Learning Mechanism
Anything that is common amongst the majority of humanity is too consistent to be left to dumb luck; it has to be a result of evolution, and thus enforced (or at least predisposed) due to the architecture. At the very least, it must additionally depend on guaranteed aspects of the environment (eg: gravity, air, sunlight vs nighttime cycle).
Some aspects of human brain behaviour require the pre-wiring of feelings, urges, desires, distastes, etc.. In some cases these can be simple electrical signals that the brain can learn online to work with. In other cases, they must require pre-wiring of network structures – ie: a whole NN “domain model” encoding. This is feasible from evolution - that some of the NN training is a result of evolution, which amounts to pre-training of the network weights (ie: not just the high level architecture).
There’s lots more discussion of this in the The Meta-Morphogenesis (M-M) Project.
Architecture
Artificial equivalents of Biological systems
Analysis of brain layers and how we’ll emulate them in an AI:
| Layer | Description | Re-interpretation | AI Architecture Layer |
|---|---|---|---|
| 1. Spinal chord | Reflexes | Mechanical layer. Reflexes. Some avenue for signal strength attenuation. eg: senses to stop motor at end of motion. | Omitted |
| 2. Brain stem | (tbd) | (tbd) | (tbd) |
| 3. Primary sensorimotor cortex | (tbd) | (tbd) | (tbd) |
| 4. Non-primary sensorimotor cortex | (tbd) | (tbd) | (tbd) |
| 5. Association cortex | (tbd) | (tbd) | (tbd) |
| 6. Frontal cortex | (tbd) | (tbd) | (tbd) |
Analysis of brain memory types and how we’ll emulate them in an AI:
| Layer | Description | Re-interpretation | AI Architecture Layer |
|---|---|---|---|
| Working Memory | Short-term executive function memory | Current working state for executive control layer | RNN state within executive control policy network |
| Episodic Memory | (tbd) | (tbd) | (tbd) |
| Semantic Memory | (tbd) | (tbd) | Bayesian models |
| Procedural Memory | (tbd) | (tbd) | Training pressure against layers |
Overview
The following systems are involved: 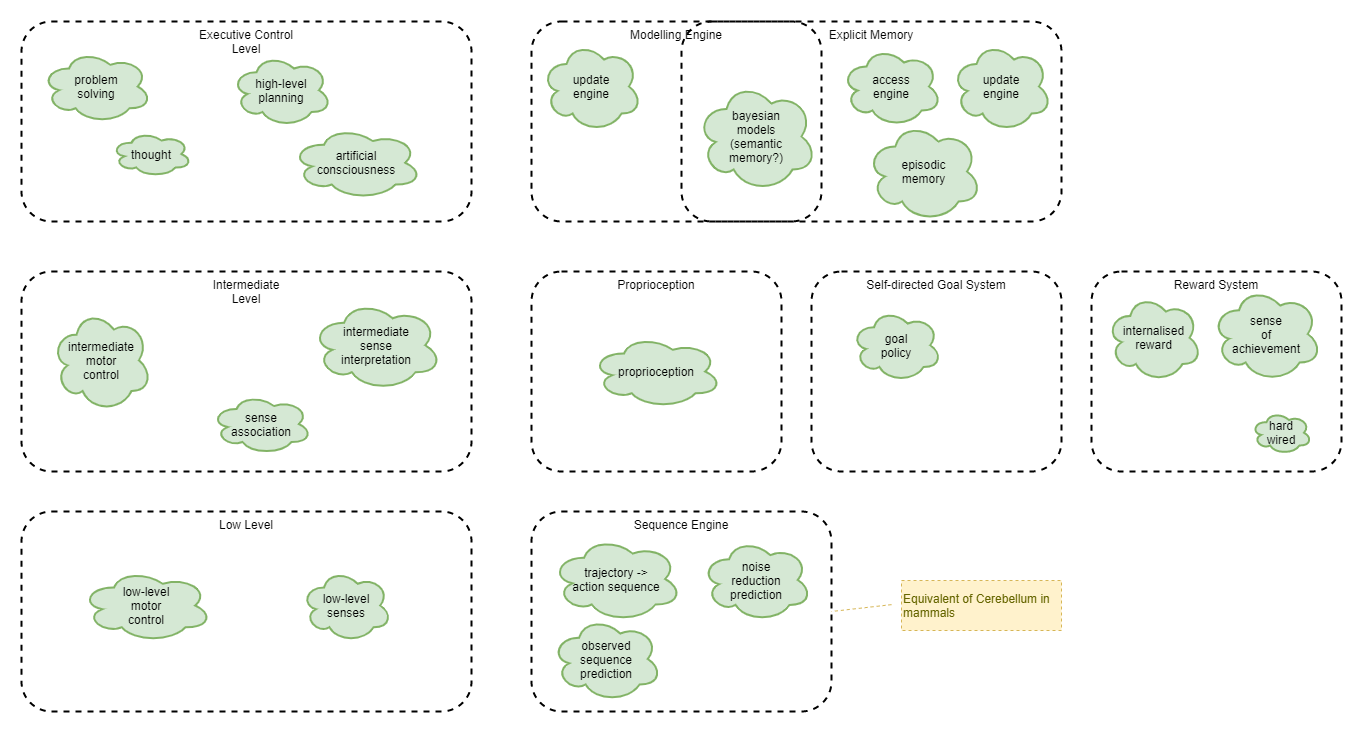
Layers
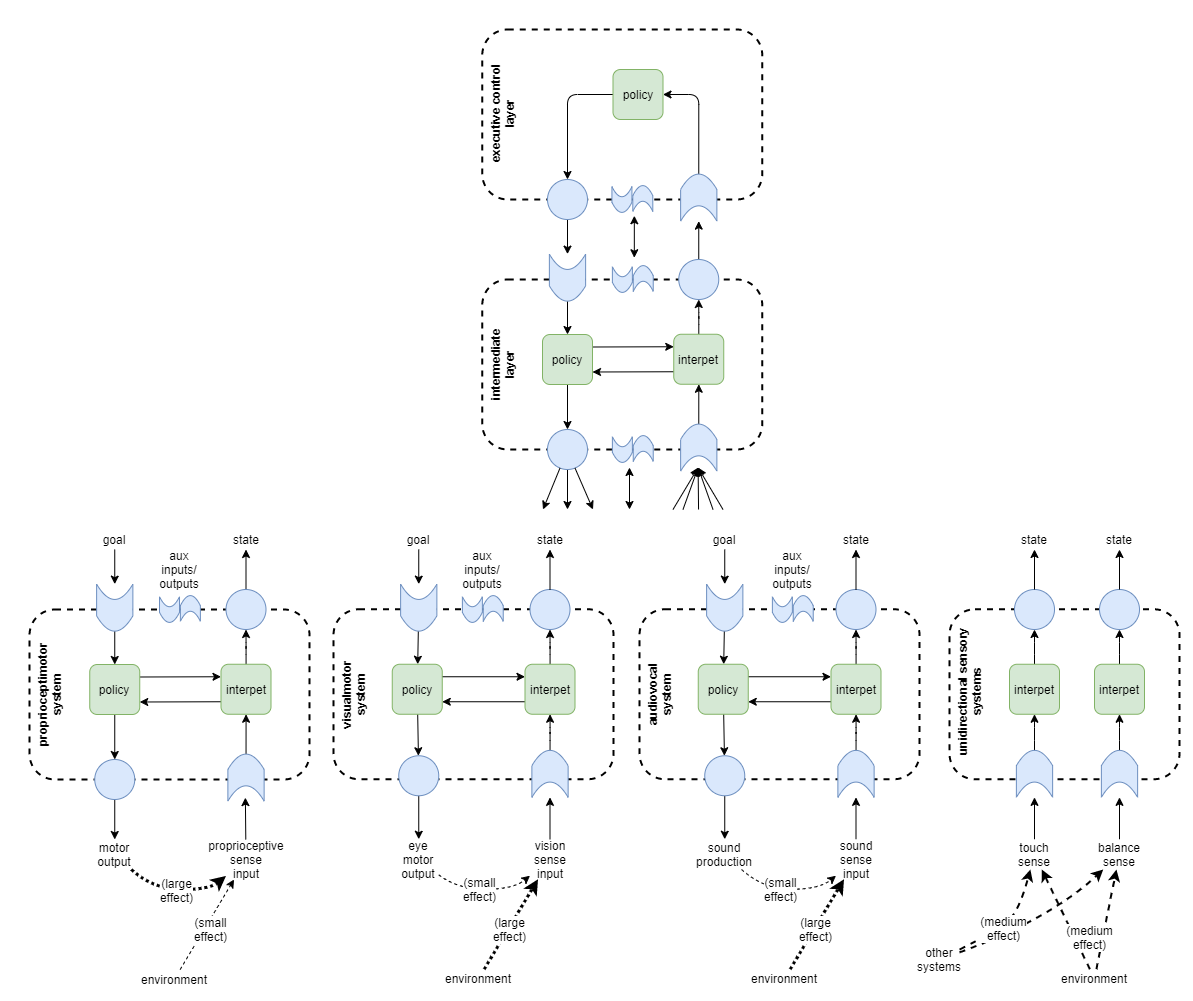
2-layer architecture
For a bit of fun, this is what a partially complete 2-layer architecture might look like that doesn’t attempt to distinguish the different sensorimotor modalities. The sections that follow shall flesh this out further and add explicit low-level support for the different sensorimotor modalities. 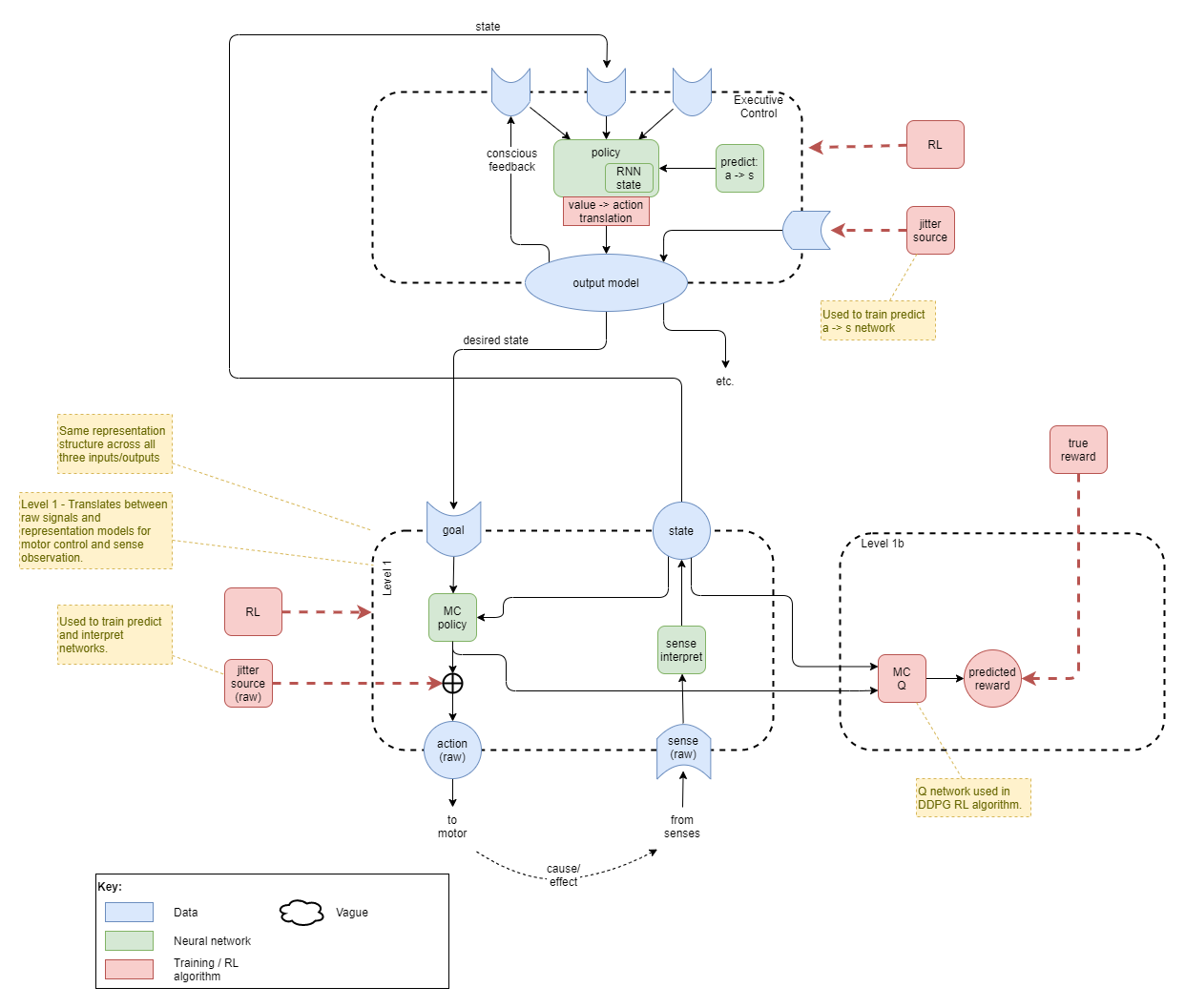
Low-level Sensorimotor Systems
The Proprioceptimotor System
Mammals don’t learn motor control through external rewards; they learn it through watching and observing. And through jitter - in the early stages of development randomly fired muscle signals cause the ligaments to move (citation needed), and the senses are used to pick up the result (particularly touch + vision). This is likely fundamental in bootstrapping a number of brain circuits. For our solution, this will be used to bootstrap the learning of two networks:
- motor control
- sense interpretation producing higher-order latent state representations from raw sense inputs
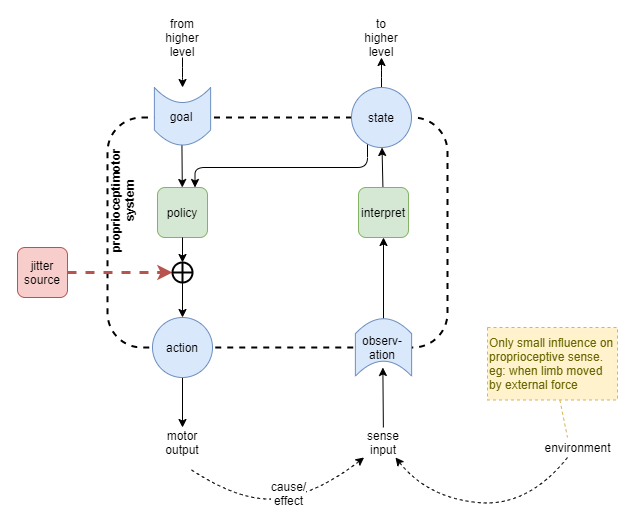
Start with randomly initialised policy and sense interpretation networks. Random jitter (noise) is injected into the raw motor control signal. This causes movement that affects the sense inputs and an update of the latent state.
For the moment we’ll ignore how the sense interpretation network is trained and focus on the motor control policy. Jitter induces an action a, which leads to an observed latent state s' one time step later. This forms an trainable observation at time t of a causing a transitition from state s to s'. So we can now collect a series of observations of the form (t omitted for simplicity):
p(s'|s,a)
We could use that to learn a predictive model of the sort that is used in model-based RL algorithms. But model-based RL algorithms are cumbersome and require a planning engine - which doesn’t seem to make sense for the most low-level motor control. So we turn the observation on its head and use it to learn the action given an initial state s and a goal g. If we force that g uses the same latent state representation, then we can train with g=s'. So, instead we build a network on the form here, and use supervised learning on the observations:
p(a|s,g)
It should be noted that use of latent state representation as goals has precedent in RL research. (Nair et _al, 2018) showed that it leads to sample efficient learning. In particular, they showed that using the latent state leads to much better results than the raw sense inputs. Additionally, they showed that with the right regularization the latent state representation can be treated as a euclidean space and distances used as errors during training. More on that in the Low level state representation section below.
Now, there are a few gotchas here.
Under the rules of probabilities, you cannot flip from
p(s'|s,a)top(a|s,s')without incorporating some a-prioris aboutp(s')etc.. In practice our approximation will be good enough given that we are only using this to bootstrap learning and we will use other processes to smooth out the errors.Jitter only enables us to observe
s'for timet+1. But when we come to use this policy, goalgis quite likely only reachable at somet+iwherei > 1, and our network hasn’t received any training for that. For now we’ll gloss over that issue with a foolish assumption that our network will generalise well enough to make reasonable guesses for the action at timetunder those conditions. In the next section we’ll use RL to train fori > 1.Even given that assumption, it is likely that we’ll run into problems of overfitting causing bad guesses. The problem is that our network capacity is significantly higher than is needed for the sparse data received so far. In humans, the initial bootstrap learning likely occurs while the brain is still developing and is much smaller than its eventual size. Thus it has less neurons to overfit with and will generalise better. In current ML, we always use fixed size networks, so we will probably need to resolve the overfitting problem here somehow.
In mammals, motor control is triggered by the primary motor cortex, but the exact sequencing, timing, and coordination with other movements is governed by the cerebellum. Exactly how that occurs is still unknown. For now we’ll build all of that into our low-level policy network, via use of a Recurrent Neural Network.
Reinforcement learning for proprioceptimotor system
Now we use RL to train the motor control policy (MC policy) for trajectories that best lead towards goal states. We’ll use the current agent’s state representation for the goals, so we do not a priori know the parameters of the reward function. We must use data collected from the current policy, or at least near to it. During the training runs in the prior section, we’ll collect the full unbroken trajectory within a sequential data buffer D = (d1, d2, d3, ....dN), where di is the tuple of data taken at time t:
(e,s,a,e',s')
where:
eande'are the true environment states at timetandt+1sands'as before are the state representations at timetandt+1ais the action taken at timet.
We’ll now sample from that buffer to produce (e,g) tuples for training: starting states and goals. There’s a few ways of choosing these. The simplest is to pick a fixed number of w at random, separately a fixed number of s' at random, and to pair them up. We don’t know how hard it is to get from any such w to s', but we’ll assume it’s always achievable under the dynamics of a safe bootstrap training environment.
An alternative would be to randomly sample short sub-trajectories from D of some random length with (with a maximum length of say 10), and then to use the first event in each sub-trajectory as the initial environment state, and the last s' as the goal. This would definitely produce trajectories that we know are achievable within a short action length, but provide less exploration for our RL algorithm, so we’ll use the first simpler approach for now and see how it goes.
We’ll assume that any goal can be achieved within some reasonable maximum trajectory length, n, with say 10 steps. This seems a reasonable starting point, as any simple limb task is usually carried out very quickly.
We’ll now run the agent under RL training conditions. For each of the training tuples selected above, we’ll initialise the environment to e, fix the goal to g, and then allow the agent to run for a maximum of n steps. Our reward function will encourage the agent to achieve a state output that matches the goal sometime within that maximum trajectory length, but also to prefer achieving it sooner rather than later. For each run, we’ll pick the state output s(t+k) that is closest to the goal g, and reward it based on how closely that state output matches the goal, and additionally discount based on how many steps it takes to achieve that best outcome. For the error measurement, we’ll just pick something simple and convenient, such as RMSE. There are some more advanced “hard-wired” rewards that we might build into that too at a later time - see the section below on Internalised Reward.
As our policy network produces deterministic continuous actions, we’ll use the Deep Deterministic Policy Gradient (DDPG)) algorithm for training.
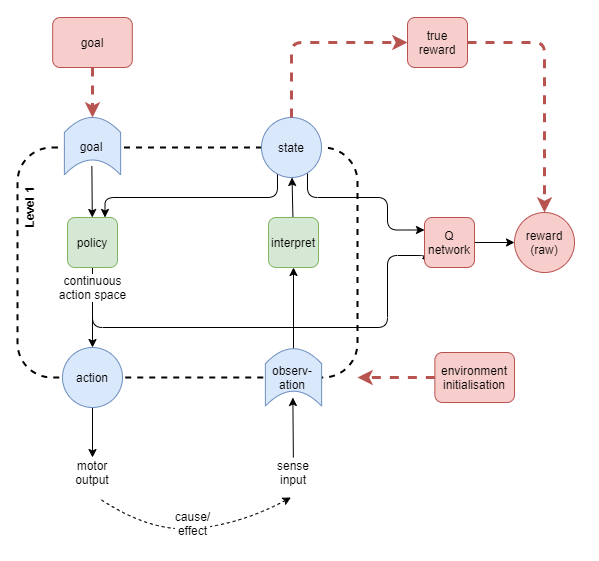
The RL learning discussed here will be alternated with the jitter and supervised learning discussed above. Thus, the low-level MC policy will accurately learn p(a|s(t),s(t+i) for all of 1 <= i <= n.
Low level state representation
How do we train the state representation that the sense interpretation network will output? In the complete architecture, the state representation will be used as input to higher level networks, and possibly the goal representation too. We don’t yet know what kind of information the high level networks will require, so we have only a vague notion that the state representation needs to be useful. This can be clarified a little by stating that it must produce a high contrast of outputs for highly different inputs. We paraphrase this vague requirement as requiring the representation to have high saliency.
There are a number of options available:
Back-prop pressure from layers above
- Depend entirely on training being applied at higher levels, with the back-propagation from that training applying a training pressure to the low level state interpretation network.
- We want to encourage convergence across multiple layers, whereas this approach depends entirely on the layer above forcing convergence, so it’s not so great on its own.
- Additionally, it means that activity that is triggered only within the low-level layer (eg: ‘jitter’ movements) will not apply any learning pressure.
Reservoir computing
- In practice, provided the state interpretation network is initialised with random weights, its initial configuration will provide a meaningful usefulness of representation even without training. This is known as reservoir computing, and its usefulness is proven and leveraged further in the theory of Extreme Learning Machines.
Future state prediction
- Under a sort of adversarial network architecture, tee off the sense interpretation network against a prediction network. The prediction network would predict the expected state on the next time step, based on the current raw sense inputs and motor control inputs. The error would be the difference between the outputs from two networks. Both networks would be trained against this error, so that they converge to the same representation.
- This approach alone will likely converge towards a ‘zero representation’, where all inputs lead to a zero output. That would be the easiest path to minimise the training loss. Additionally, assuming that the networks are randomly initialised with a distribution having mean zero, the shared loss will on average encourage both networks towards zero.
- Thus it will need to be paired up with something to increase saliency. For example the ‘gram matrix’ used in the neural style transfer TensorFlow tutorial, or some other mutual-information metric.
Reward prediction
- Use the state representation as input to predict the reward received, and to use supervised learning to train a Q network with backpropagation into the state interpretation network.
- The intuition here is that it will ensure that the state representation has sufficient saliency for accurate reward prediction.
- The problem is that, in the section above on low-level motor control training, our choice was to reward motor control policy based on the current state representation. So this approach doesn’t add anything that isn’t already there.
- A solution could be to use ground truth values for motor control reward (ie: actual limb positions), and then a reward prediction network off the state representation could lead to something useful. However, this depends on external rewards, and we want to train the agent using intrinsic rewards – especially for the low-level networks.
Variational autoencoders
- An approach that has been successfully applied by other researches is to use a Variational Autoencoder (VAE).
- Like the prediction approaches above, autoencoders tee off two networks against each other. They use the idea that the sense-interpretation network from raw sense to higher level representation is an encoder, and thus there can exist a decoder which does the opposite. By feeding the encoder output into the decoder, the final output should be something similar to the raw sense inputs.
- VAEs are autoencoders with an additional regularization that ensures a smoother representation space. The intuition is that similar raw inputs should lead to similar encoded representations. However, in practice it has been observed that simple autoencoders produce chaotic results with similar raw inputs leading to very different encoded representations. So a regularization term is added to training to smooth that out.
- This has an added bonus that the representation space now operates as a euclidean space and you can compute distances between two state representations (Nair et _al, 2018).
- The idea of pairing up a forward and a backward facing network seems to fit quite well with the Adaptive resonance theory of biological brains.
I suspect that the best result is a combination of:
- Variational autoencoders
- Back-prop pressure from layers above
- Use of a good state space exploration learning approach such as the jitter signals discussed above or the Diversity Is All You Need (DIAYN) approach of (Eysenbach et al, 2018).
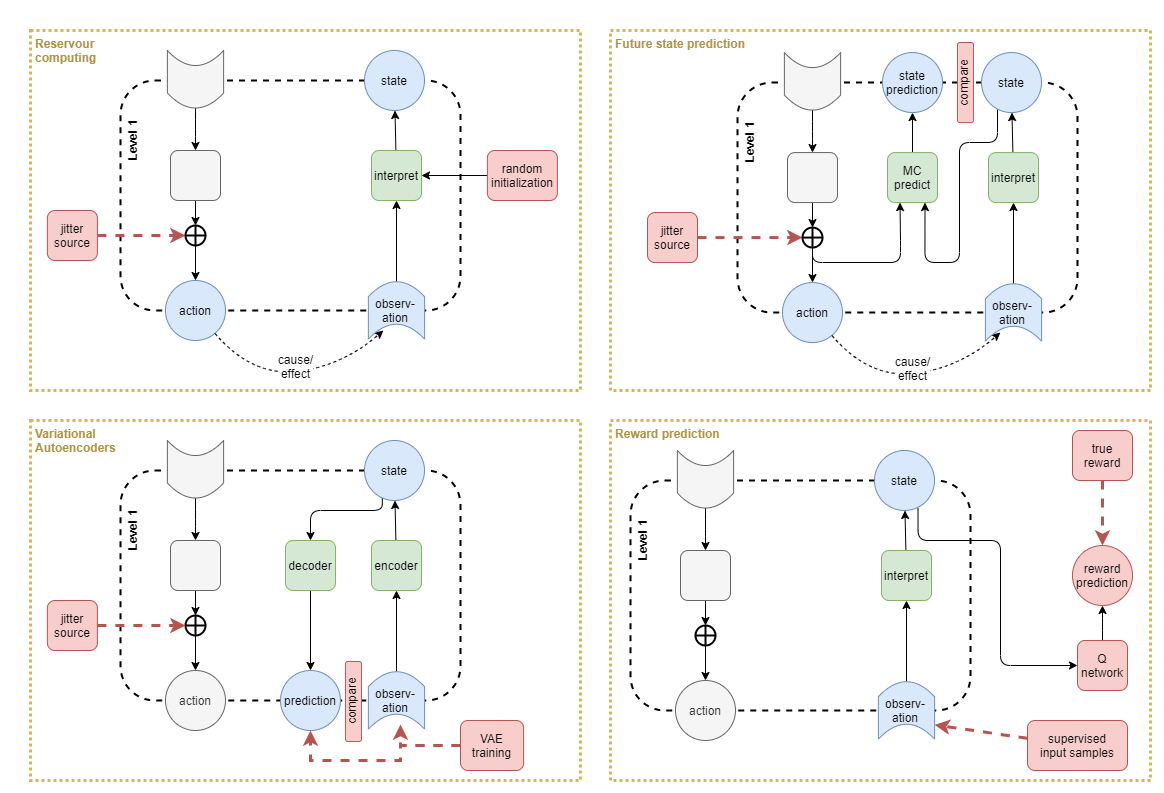
Body schema
In humans, proprioception is achieved through aggregation of direct senses and through mental tracking of limb position. It depends on three distinct physical senses, listed in order of highest significance first: i) muscle spindle fibres plus golgi tendon organs, ii) skin, and iii) vision (Proske & Gandevia, 2012). The muscle spindle fibres and tendon organs do not alone accurately track limb position because they encode joint angles, but not limb length. Thus the brain also maintains a body schema that mentally tracks the position of limbs, using input from the senses mentioned (Proske & Gandevia, 2012. section 4a).
In contrast to most other senses, in humans the raw proprioceptive senses are not consciously accessible. Rather we appear to be aware of the current state of the body schema. For example, you can lie still, close your eyes, and know where every part of your body is - but it’s believed that you don’t experience any direct awareness of the muscle spindle fibre senses. Furthermore, while you may not be consciously attentive to the proprioceptive sense at all times, that information is always available. This is in the same way that the touch sense of your clothes on your skin is available available, but you are only attentive to it occassionally.
Putting that together, we have the following components for prioprioception and body schema awareness:
- Lowest level sensorimotor system trained via raw motor outputs and raw proprioceptive senses, probably with no input from even skin touch sense, and definitely none from vision.
- Touch and vision senses fed into association cortices – aka intermediate layer.
- Intermediate layer combines proprioceptive senses with touch and vision senses to maintain body schema
- Intermediate layer uses body schema to help plan movement
- Intermediate senses feed into proprioception system in order to train proprioceptive model and update proprioceptive state (eg: apply error correction)
- High level body schema state fed in as input to executive control layer.
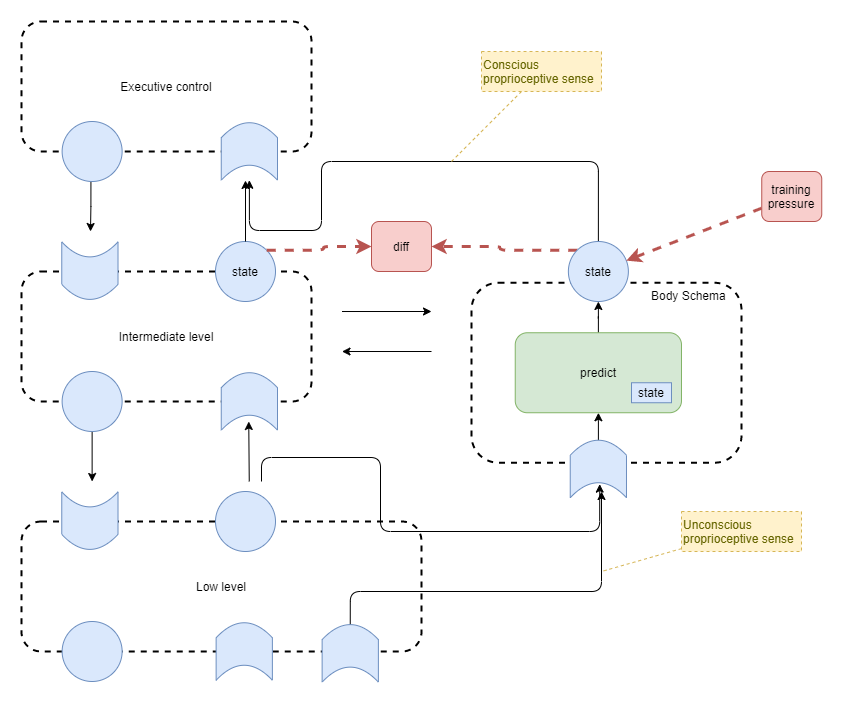
Body schema training
In order to train the body schema system, need to tee off the following against each other:
- proprioceptive prediction of location of limbs
- visual interpretation of location of limbs
- ability to use that to predict accurate movements
- eg: use error in final state when attempting to grasp something.
Also:
- Train to predict next state given current action
- Corollary: predicts current state given no planned action.
tbd:
- Which level of state representation to use for training?
Ocular System
Drawing inspiration from proprioceptimotor system, a first draft of an ocular system is as follows:
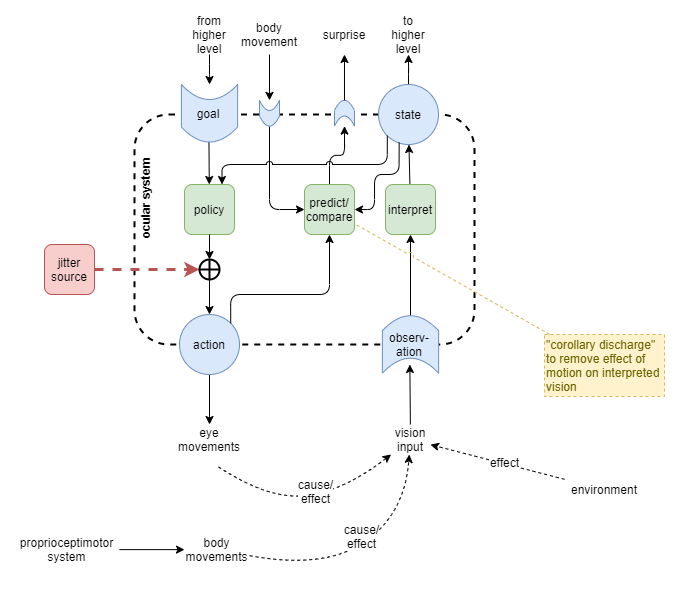
Corollary discharge, and the closely related term efference copy, have an important part to play in the ocular system for predicting the effects of movement on vision. The visual image changes entirely due to agent for any of the following reasons:
- main body moves, moving the eyes with it
- eye angle changes
- eye focus changes
Corollary discharge is achieved by predicting the effect of those changes on the visual input, and removing the “surprise” from the image change as a result. This plays in the reverse too: if an attempt is made to move the body or eyes and the perceived image does not change in accordance, then this should lead to surprise.
Audiovocal System
Similar to ocular system.
Has similar corollary discharge mechanism to remove one’s own production of sound from the ‘surprise’ signal. And the inverse of that: surprise at not producing sound.
Areas Requiring More Work
Where and What systems
(tbd)
Intermediate Layer
(tbd)
Intermediate Layer Training
So, how to actually train the intermediate layer?
Factors to consider for training
As the intermediate layer is totally internal to the agent, it is harder to apply direct reward measures or training losses. There are multiple factors that influence how best to apply RL training to the intermediate layer.
Representational Gradient:
- Back-prop pressure from layer above.
- Representation bandwidth from layer below.
- Discussed further within “Overall Training Approach”
Goal Representation from Below:
- The need for DIAYN at intermediate layer in order to discover the low-level layer’s goal representation.
- Discussed further within “Overall Training Approach”
Resultant training strategy
Based on the above notes, the training of the intermediate-level will be a combination of:
- back-propagation from high-level and low-level component training.
- training during RL that incorporates the support components (ie: body schema)
- DIAYN
Lastly, the following narrative provides some observation:
- I want to eat. I want my hand to put the food into my mouth. I don’t care how it gets there as long as it doesn’t drop the food, it doesn’t hurt me in the process, and it basically follows an efficient path.
- My goal is a high-level concept of “food in mouth”.
- I’ll actively monitor the arm and provide internal reward to myself if I achieve my high-level goal.
- And it would appear that the level of that high-level goal is a result of the representational gradient and other pressures as described within this document.
Executive Control Layer
tbd
Absolute vs Relative Control
In this context, “absolute” refers to a goal or action representation that entirely encodes the full desired state, including ambient background state that isn’t relevant to the task at hand. This can be a complex option for controlling a particular focused task, particularly when the ambient state may itself be changing independently. “Relative” is used to refer to any means of producing only a partial representation that focuses only on the task at hand. Additionally at times we will distinguish “static” motion (I want my hands to go to a particular position and stop there) from “dynamic” motion (I want to swing my axe in a chopping motion). And we’ll also distinguish “continuous” motion (that requires continuous action signal for duration of motion) from “persisted” motion (begins from a ‘start’ signal and then can continue without further exec ctrl).
Intuitively it would seem like we need to support relative goals and actions somehow, because that’s our experience as a conscious agent. I can keep walking while my mind drifts off. In practice, I think that’s better treated as a later optimisation tray someone wise will figure out. I can imagine an evolutionary path where the executive control layer works only in terms of absolute goals and actions initially, and then later frees up executive control by holding state in lower levels so that the exec ctrl layer only needs to send a signal when it’s time to change the persistent request.
There are a number of options available for supporting relative representations.
Zero is off
- Treat numbers near zero as “ignore” signals, and thus ignore them when calculating the error between goal and actual (presumably work some sort of soft-off).
- Suffers from an inability to natively represent meaning via near-zero numbers because they’ve now been reserved for a meta signal. This will push the network to jump through hoops when it does need to represent zero, such as offsetting by some fixed amount.
Control mask
- Double the size of the representation with the second copy being a mask, and use it as above.
- A mask provides similar capability to Zero-is-off but with a different drawback of doubling the state space. Also, there is a risk that the policy will start using as few nodes as possible for the goal representation, masking all the rest off, so that it’s easier to achieve maximum reward (from the goal vs actual error). It’s possible that this risk can be mitigated by applying the same mask to the action output, so that it is forced to produce meaningful action representations. However, given that the mask is a separate signal, there’s no reason why the lower layer would even use it, so it doesn’t sound very effective.
- In fact, the Zero-is-off approach is looking much better. It naturally encodes the mask in a way that the lower layer has to recognise. And because of that it solves the problem of the mask reducing towards only one active node. It also has a precedent in biology in the way that zero means no spiking, and that obviously encodes to no action.
Global attention
- Extension to above where everything in executive control layer is masked by the same attentional control.
Delta
- Action signals from exec ctrl are deltas applied to some persisted current request.
- Delta signals primarily relate to continual vs persisted motion. It requires something to hold the state. Options for that are: hope that the exec ctrl RNN will handle it, hope that the intermediate layer RNN will handle it, or add a hard wired primitive component in between the two that holds the state and effectively acts as a translation layer from delta to continuous absolute signals. Cons with primitive approach: blanket rule that everything must be delta is too simple. Con with delta: quickly leads to +ve or * ve saturation of persisted values.
One of the biggest problems with all these options is that they presuppose that all actions operate under the same mode. The reality in biology is probably significantly more complex, with different actions operating under different modes. For example, in biology some parts are likely handled at the low level synaptic and recurrent level. Synaptic cycles are known to exist with separate “off” signals (eg: in primitive pain signalling). So, for something as primitive as walking, it is likely a delta signal from exec ctrl layer, with state handled within the intermediate and low levels. But for many other actions I need to continually produce the action signal: if I stop thinking about doing something, my body stops doing it.
Distributed Predictions
There are several additional inter-layer connections that can be added to aid in predictions that help with both sense interpretation and motor control. This chapter reviews some of those.
Handling Noisy Data
In humans, the upper layers predict what they expect to observe based on the current context. This is particularly evident in the case of some mild hallucinations (WUSM, 2021), eg: when hallucinating specific noises in the presence of random background noise.
Those predictive signals from higher-order layers help the inference within lower-level layers in the presence of noise. That would look something like this:
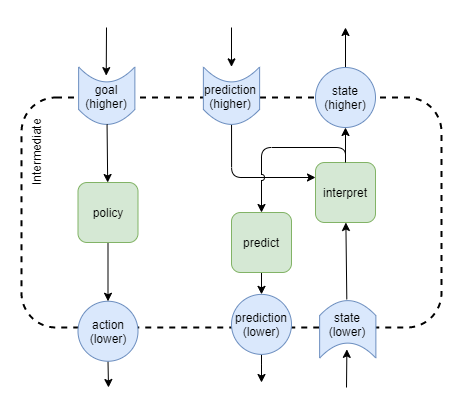
Next state prediction
It can be useful to predict what will happen next. Uses of this include:
- simulation of actions - how would an action play out if executed?
- early warning following action - System 1 signal that outcome isn’t going to be what executive control layer wanted following the initiation of an action sequence
- observation prediction - predict trajectory of ball
Applying an architecture as per this diagram could help:
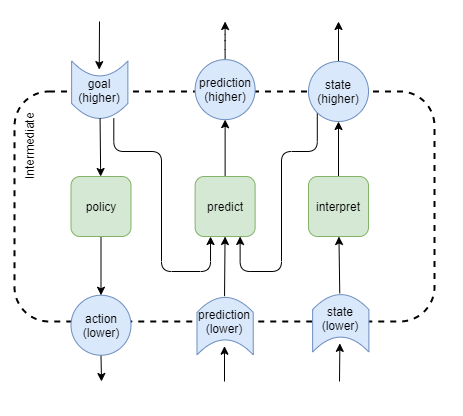
The prediction network would be trained through a replay buffer, with the prediction error becoming the training loss. Of note are the representational levels implied in this diagram:
- 2 inputs at higher-order level, plus
- 1 input at lower-order level, and
- 1 output at higher-order level.
There will be some variations across the layers:
- Low-level layer doesn’t have a prediction from a lower level layer - it might make sense to feed the raw motor control output plus raw sense input as an alternative low-level input, as this would provide the raw details needed for accurate prediction.
- Executive control layer doesn’t have a higher-order layer to feed the prediction to - feed the prediction into the executive control policy instead.
Another thing to consider is how far into the future the prediction should be. Should each layer just predict the next state for the next time step? Perhaps the low-level layer predicts the next time step, the intermediate layer predicts over a longer period of time, and the executive control layer predicts over an even longer period of time. Training with fixed prediction time intervals is easy with a trajectory cache. It would seem that varying time interval predictions would make more plausible biological sense, but it’s not obvious how we’d achieve that.
Corollary Discharge
(tbd: discussed within applicable low-level layers, so just summarise here)
Overall Training Approach
Repeated cycles of the following sequence of training:
- RL of Level 1 with jitter as input
- Supervised Learning (SL) of Levels 1 + 1b with generated sense inputs
- RL of whole network with jitter against executive control output (?)
- RL of whole network with full policy execution
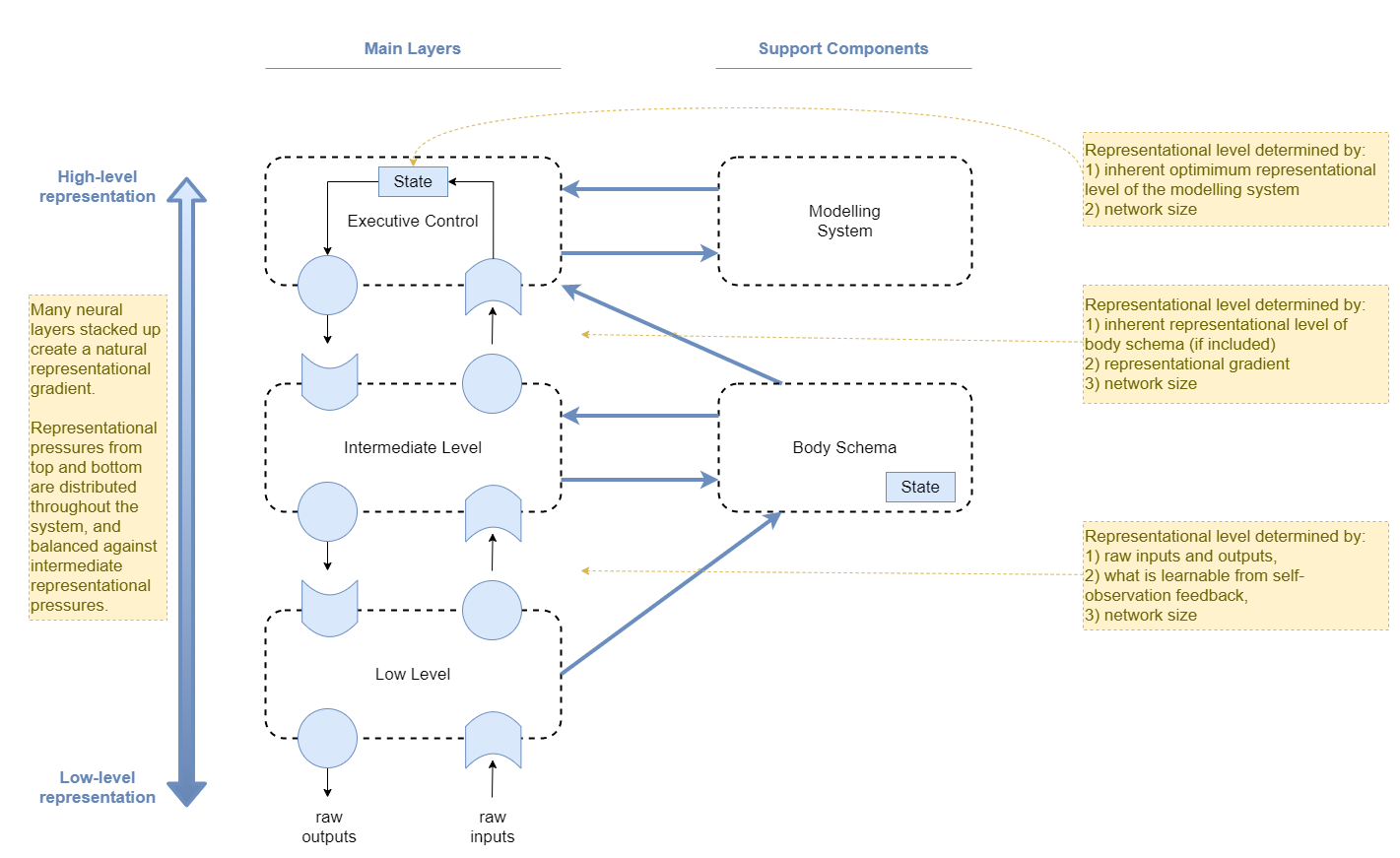
Representational Gradient
The current design of the low-level sensorimotor systems will tend to use fairly low-level representations at their interfaces to the layer above. This is because i) they have minimal training pressure applied from the layer above, and ii) they are trained on instantaneous sense inputs without time-sensitive context (ie: it will represent motion at level of “arm is moving up at speed x”). And the goal input to the low-level will have that same level of representation.
Thus, the low-level will not learn medium level representations like “move arm towards mouth in eating position”. This fits well with observations from brain stimulation in monkeys.
To build up a higher level system, we need to enforce a higher level of representation. An important aspect of the system is that it is made up of many neural net layers stacked on top of each other. From raw sense input up to executive control, each layer integrates the data from below into a slightly higher representation. From executive control down to raw motor control, each layer differentiates the data from above into a slightly lower representation. Across the system, this applies a pressure that is distributed between top and bottom, creating a representational gradient.
In a biological system, each component in the higher-order layers must have characteristics that work best given a particular representational level and structure. That must apply a convergence pressure on the components that it interacts with. And each other component presumably has similar effects on the components around it. The assumption here is that the final result naturally tends towards an equilibrium. Lastly, evolution will have tuned all those inherent component characteristics so that the system as a whole produces “fit” results.
For our solution, the representational levels will be found through convergence of pressures illustrated here:
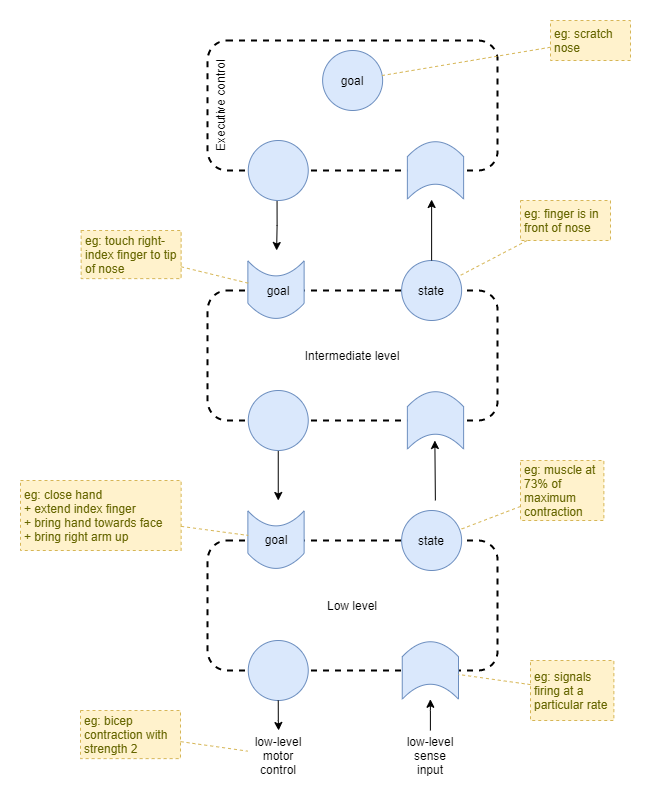
Hierarchical goal and state example
Translating human representational hierarchies onto the diagram above, we would have something like this:
Reward Layers
The low level motor control will be primarily trained using:
- DIAYN - converges towards outcomes modelled as a function
f1(goal) -> unique statethat is as diverse in outcome states as possible. - backprop pressure from above - converges towards outcomes modelled as
f2(goal) -> desired statethat hopefully reflects the interpreted desires from the intermediate layer. - primitive efficiency error - influences the trajectories taken to reach the outcomes above
However there is no reason that the first two pressures above will lead to the same function. The intermediate layer knows nothing of the particular goal representations produced by DIAYN within the low level layer.
A solution is to employ DIAYN at all levels, so that each higher-level layer can discover semi-optimum output action representations for commanding the lower-level layer.
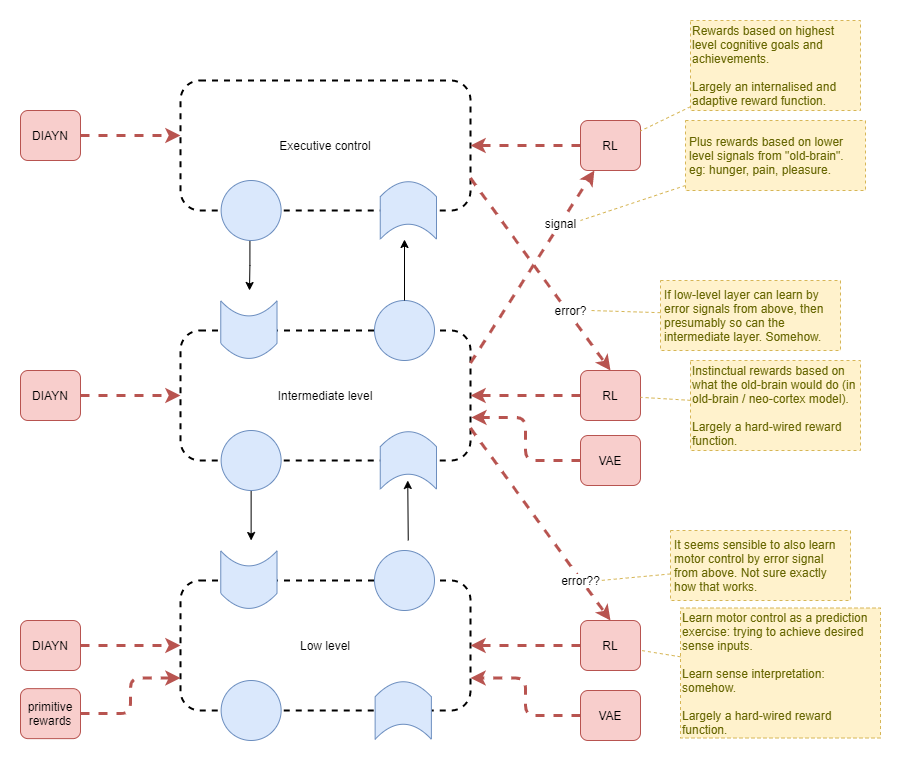
As each lower-level layer is also learning and changing its behaviour, the overall system will initially be highly chaotic. But the mechanisms applied to encourage convergence at each level independently will ultimately result in the whole system converging. That initial chaotic nature serves the highest level well as it executives a broad search for optimum policy. Primitive efficiency error will help to lead to smooth motion.
During this time, mental models are also being built up from observations. Eventually the executive control layer will start to produce stable goals and attempt to action them. The goals will initially be based on trying out existing mental models about past learned motor skills, but will later be more driven by goal exploration.
As goal driven exploration takes over, the DIAYN signal will reduce slowly towards zero. ie: reduced induced random noise and reduced RL loss signal from DIAYN algorithm.
Hierarchical Learning
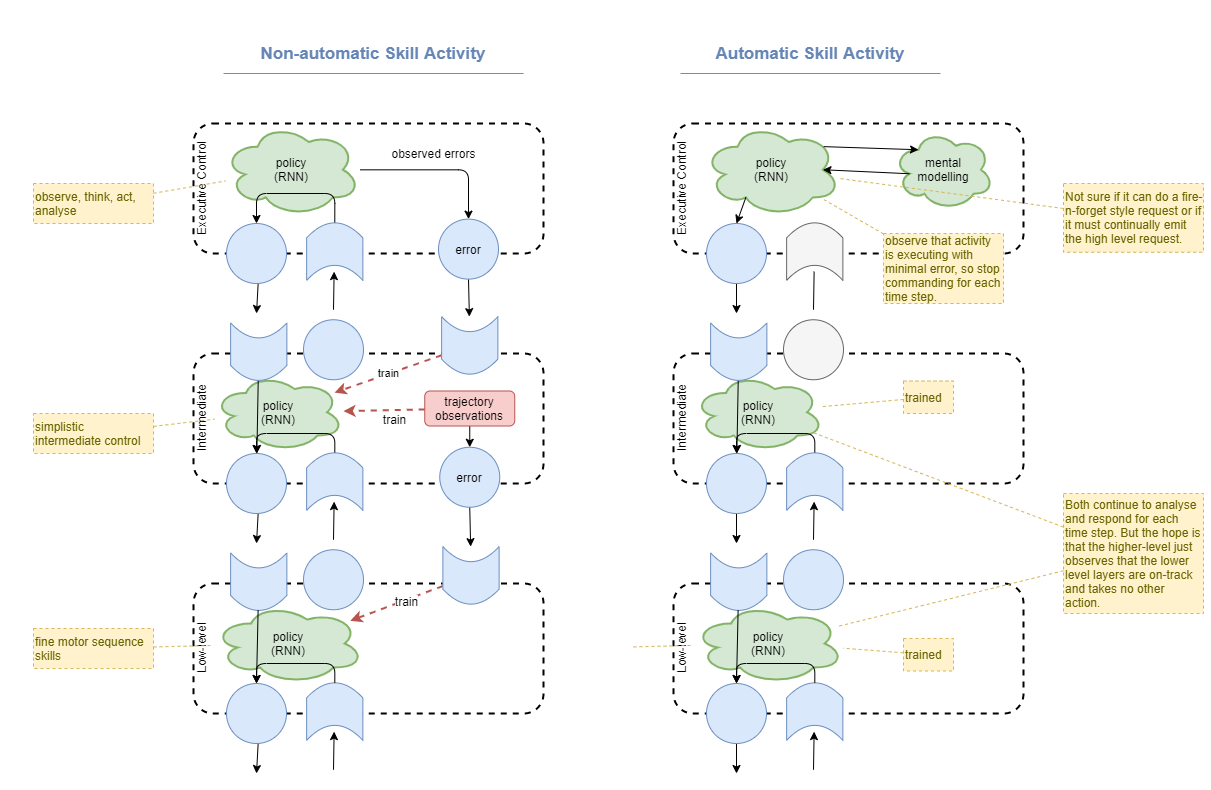
Hierarchical action errors
- Executive control layer: Send “desire signal” from top layer. eg: “touch finger to nose”
- Executive control layer: Observe error, record, and send from executive control layer to intermediate layer.
- Executive control layer and Intermediate Layer: record observation tuple
<desire, error>. - Executive control layer: In training round, use
<desire, error>tuple to move slightly towards producing a better desire signal that would produce a better outcome (assuming a fixed intermediate layer network). Additionally, this probably applies back-prop pressure to intermediate layer. - Intermediate layer: In training round, use
<desire, error>tuple to move slightly towards doing the better action given a fixed desire signal from the executive control layer. Additionally, this probably applies back-prop pressure to low-level layer. - And mental modelling will record how much executive control was required in order to achieve the desired state.
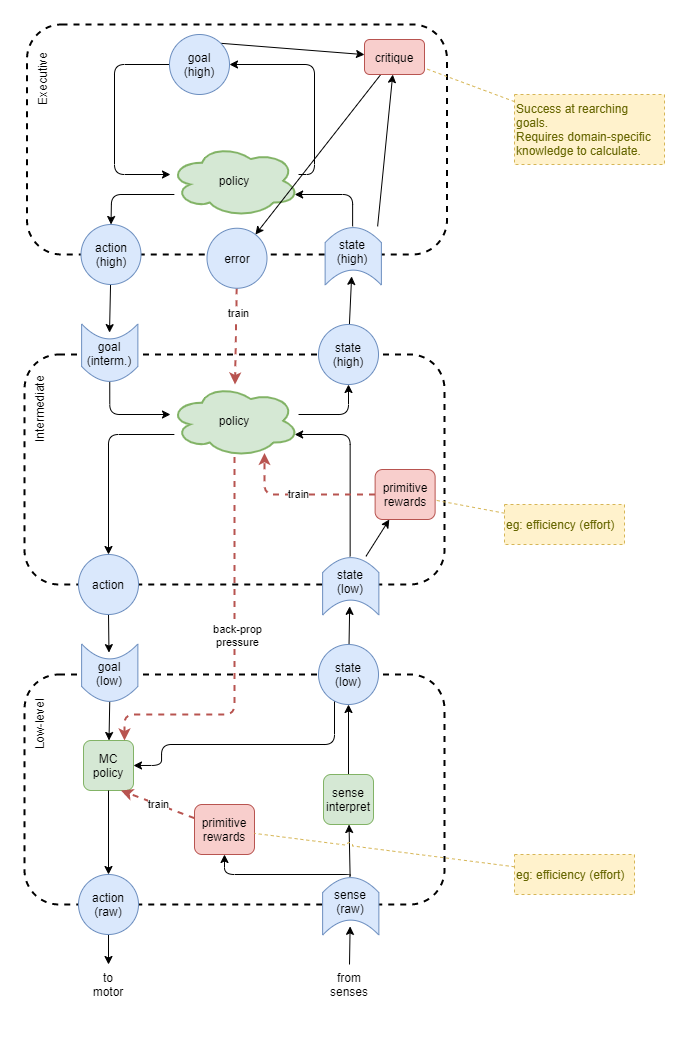
Capabilities Development
Our training approach needs to consider that some capabilities cannot be efficiently developed without first developing lower-level capabilities. This creates a dependency graph, which can be represented as follows:
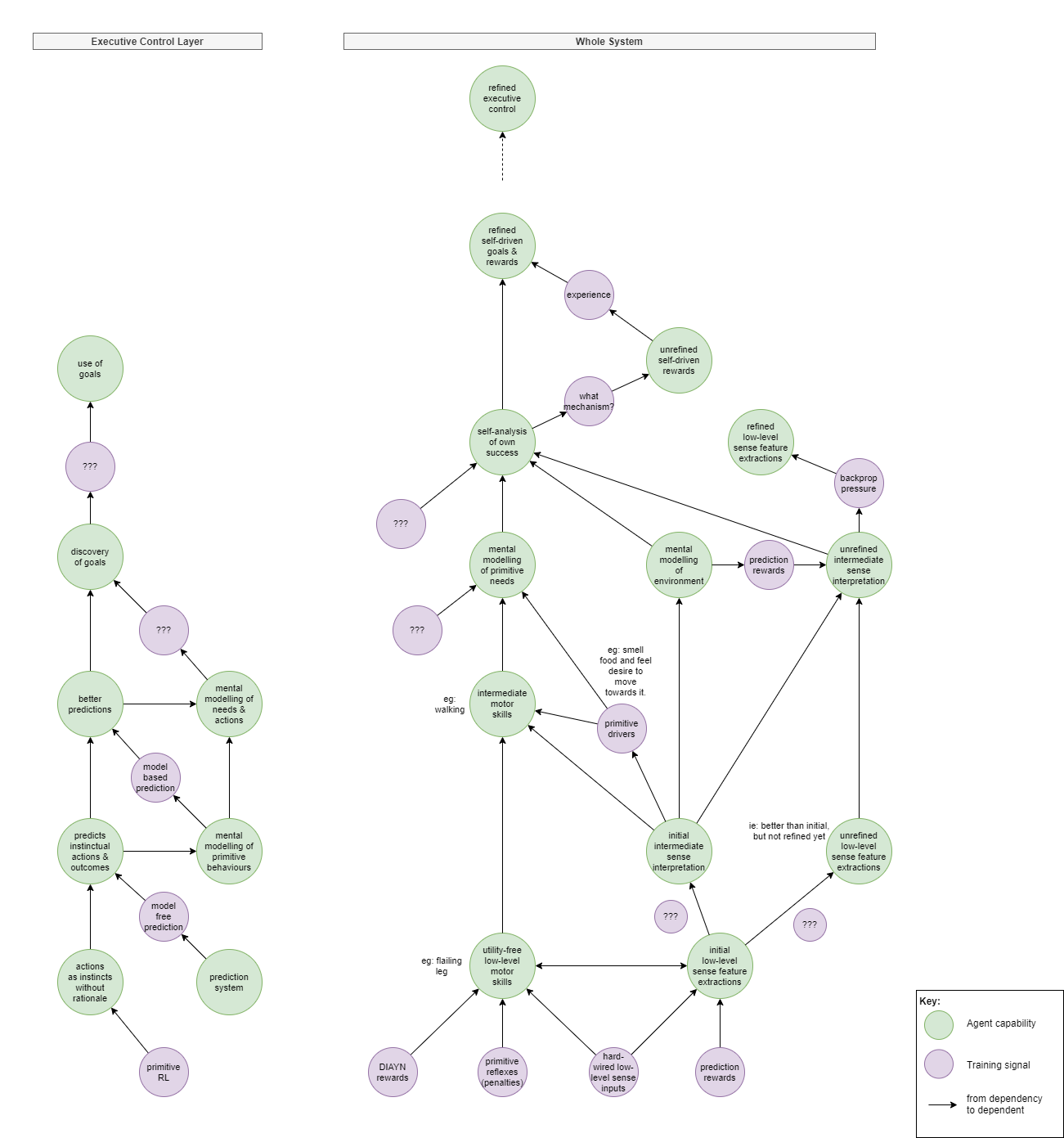
wip….
From point of view of observable outcomes:
- Learn utility free “skills” from mutual information metrics via DIAYN.
- Outcome: discovers bunch of disjointed utility free actions. Primarily low level, but may include some intermediate “skills” too.
- Outcome: some vision feature detections will be in place, but unrefined. Hopefully some prediction linking motion to sense changes. Limited to no meaning interpretation. And given that accurate sense prediction, with attention, requires higher level control, this will be quite inaccurate.
- However, eg: without any driver to learn to walk, it won’t necessarily do so.
- Learn intermediate skills from primitive drivers
- Needs a driver. But I don’t want to use the kind of hidden-sourced sparse rewards that traditional RL uses.
- Babies use intermediate-level primitive instincts. Eg: smell food and move to it.
- Subsequently: can observe own actions and cause /effect to build mental model about hunger and food.
- Learn intermediate skills from external rewards
- Reward with food, pleasure, pain.
- Outcomes: improves mental models.
The abilities of the executive control layer will need to be bootstrapped via naive RL, and for this to slowly feed into mental models that later enable the production of goals. This looks something like:
- Primitive RL without any self control
- To a self-aware agent feels like across successive experiences its instinctive actions change over time to a different outcome.
- No experience of the error or reward signals or the learning.
- Model free Prediction
- Starts to predict that a particular sense observation is typically followed by an instinctual action and an outcome.
- Self aware agent now becomes aware of the prediction that certain actions and outcomes are about to follow.
- Model based prediction
- Draws connection between primitive experience (eg hunger), the outcome that resolves the experience, and the actions that can get there.
- Self aware agent “understands” in a very primitive sense why it instinctively performs the actions it does.
- Discovery of goals
- Somehow this translates into a model about its ability to have goals.
- (need to investigate this more)
- Use of goals
Phases
Just like humans learn in phases, with particular focuses, we can apply the same here. In particular, it may prove useful to disable high-order systems initially.
| # | Focus | Description | Dependencies |
|---|---|---|---|
| 1 | Somatosensory + sensorimotor | . | . |
| . | … | . | . |
| . | visual proprioception | . | modelling engine |
| . | … | . | . |
| . | conscious control | . | . |
Measuring success
How will we tell if all this effort is worth it?
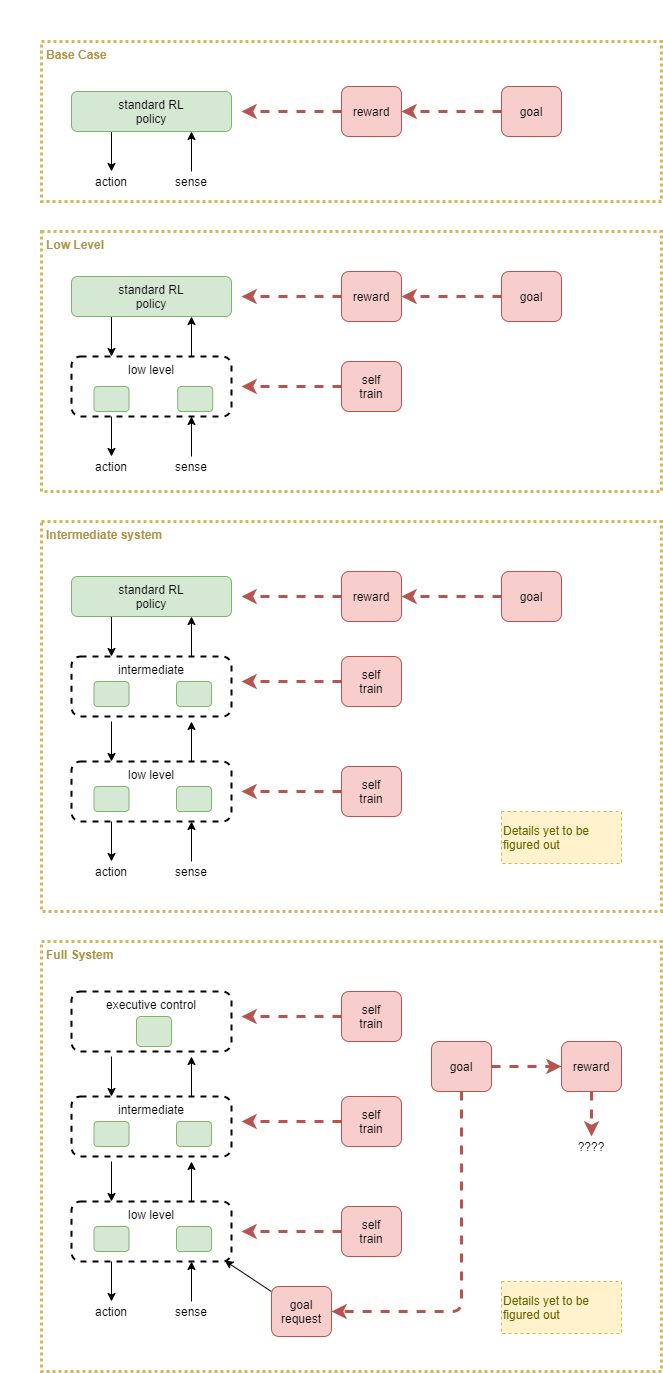
Let’s compare against the results of using standard reinforcement learning, then slowly build up the layers, using a standard RL policy on the top, until we have a full system.
We’ll need to decide on a sensible goal, or set of goals, to experiment with. Then compare those by looking at:
- success rate at achieving goal
- learning time
- “smoothness” of actions
- “efficiency of actions”
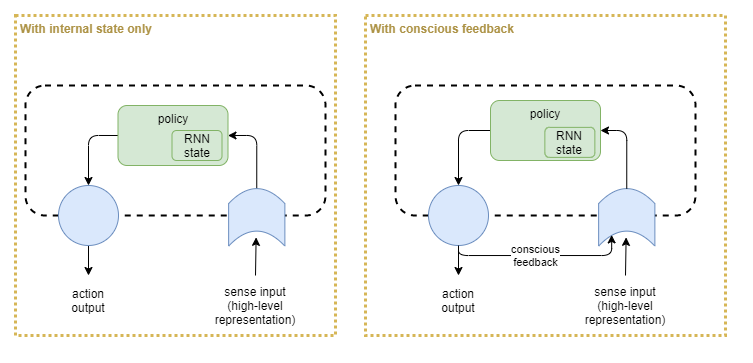
Measuring Use of Conscious Feedback
Recurrent neural networks (RNNs) were designed to apply against sequences on the inputs. They were not intended for maintaining long term state – such as required in order to sustain internal thought. So do we need an explicit concsious feedback loop that feeds last cycles’ output as input to the next cycle? Let’s test that.
How to measure utility of an explicit conscious feedback loop, vs just depending on internal state within a stateful policy (ie: RNN)? Use each of these configurations, and train on something simple but that requires processing loops in order to succeed.
Measuring Benefits of Hierarchical Architecture
We want to prove that we’ve produced a worthwhile hierarchical RL solution.
The proposed architecture produces a representational hierarchy. But what about a temporal hierarchy? The time steps are still the same frequency at the lowest and highest levels of the architecture. But maybe the executive control layer copes anyway and produces the effect of a temporal hierarchy. An ideal world be if the executive policy just calculates the goal, based on past inputs, and holds that goal constant until it had been reached. In other words, that it feeds a constant goal to the intermediate level.
We wouldn’t achieve much by trying to force that, but we can measure the extent to which it does or does not do that. Treat executive control’s output vector as a euclidean space and measure distance to some fixed reference point. The value should be fairly consistent at the moment of achieving a goal, so take that as the reference point and compare the value at all other time steps to that reference. Do the same for all levels. If measuring across a sequence of goals, use that first reference point across all runs
Expect to see the executive control pretty constant, the low-level layer all over the place, and the intermediate layer in between.
References
Eysenbach, B., Gupta, A., Ibarz, J., and Levine, S. (2018). Diversity is All You Need: Learning Skills without a Reward Function. ArXiv. https://arxiv.org/abs/1802.06070
Nair, A., Pong, V., Dalal, M., Bahl, S., Lin, S., and Levine, S. (2018). Visual Reinforcement Learning with Imagined Goals. ArXiv. https://arxiv.org/abs/1807.04742
Proske, Uwe; and Gandevia, Simon C. 2012, Oct. “The Proprioceptive Senses: Their Roles in Signaling Body Shape, Body Position and Movement, and Muscle Force”. Physiological review. https://doi.org/10.1152/physrev.00048.2011 (full text).
Washington University School of Medicine. (2021, April 1). Mice with hallucination-like behaviors reveal insight into psychotic illness: Study in mice and people offers new approach to investigating mental illnesses. ScienceDaily. Retrieved April 7, 2021 from https://www.sciencedaily.com/releases/2021/04/210401151253.htm
(Added 2021-02-03. Labels: work-in-progress)